Getting start with automl-engine¶
Get best models with only 3 lines of code no matter what type of data with automl-engine.
How to create machine learning and deep learning models with just a few lines of code by just provide data, then framework will get best trained models based on the data we have? We don’t need to care about Data Loading, Feature Engineering, Model Training, Model Selection, Model Evaluation and Model Sink, even RESTful with best trained model.
Now automl-engine comes in to show power!
This repository is based on scikit-learn and TensorFlow to create both machine learning models and nueral network models with 3 lines of code by just providing file or sklearn training style, if there is a test file will be nicer to evaluate trained model without any bias.
Installation¶
Warning
It’s highly recommended that to create a virtual environment to install automl-engine as automl-engine will use many data science packages that needed to be installed.
Linux
Install virtual env:
sudo apt-get install python3-venvCreate virtual env folder:
python3 -m venv your_env_nameactivate your virtual env:
source your_env_name/bin/activateInstall lastest
automl-enginepackage:pip install automl-engine
Windows
Install virtual env:
python -m pip install virtualenvCreate virtual env folder:
python -m venv your_env_nameactivate your virtual env:
.\your_env_name\Scripts\activateInstall lastest
automl-enginepackage:pip install automl-engine
Quickstart¶
Sample code to use automl-engine package by using Titanic dataset from Kaggle competion, as this dataset contain different kinds of data types also contain some missing values with different threasholds.
>>> from automl.estimator import ClassificationAutoML, FileLoad
automl.estimator is main part for automl-engine that contains both ClassificationAutoML and RegreessionAutoML.
>>> file_load = FileLoad(file_name="train.csv", file_path = r"C:\auto_ml\test", label_name='Survived')
- mod
FileLoad is a container for storing our dataset and label, support with
Cloud storage. Just provide training file name with file path.
Please keep in mind to tell FileLoad which label to use, otherwise will use the last column as label.
>>> auto_est = ClassificationAutoML()
>>> auto_est.fit(file_load=file_load, val_split=0.2)
Based on dataset size, training process will be vary, after a few mins that we could get engine’s output with format string in console based on validation score.
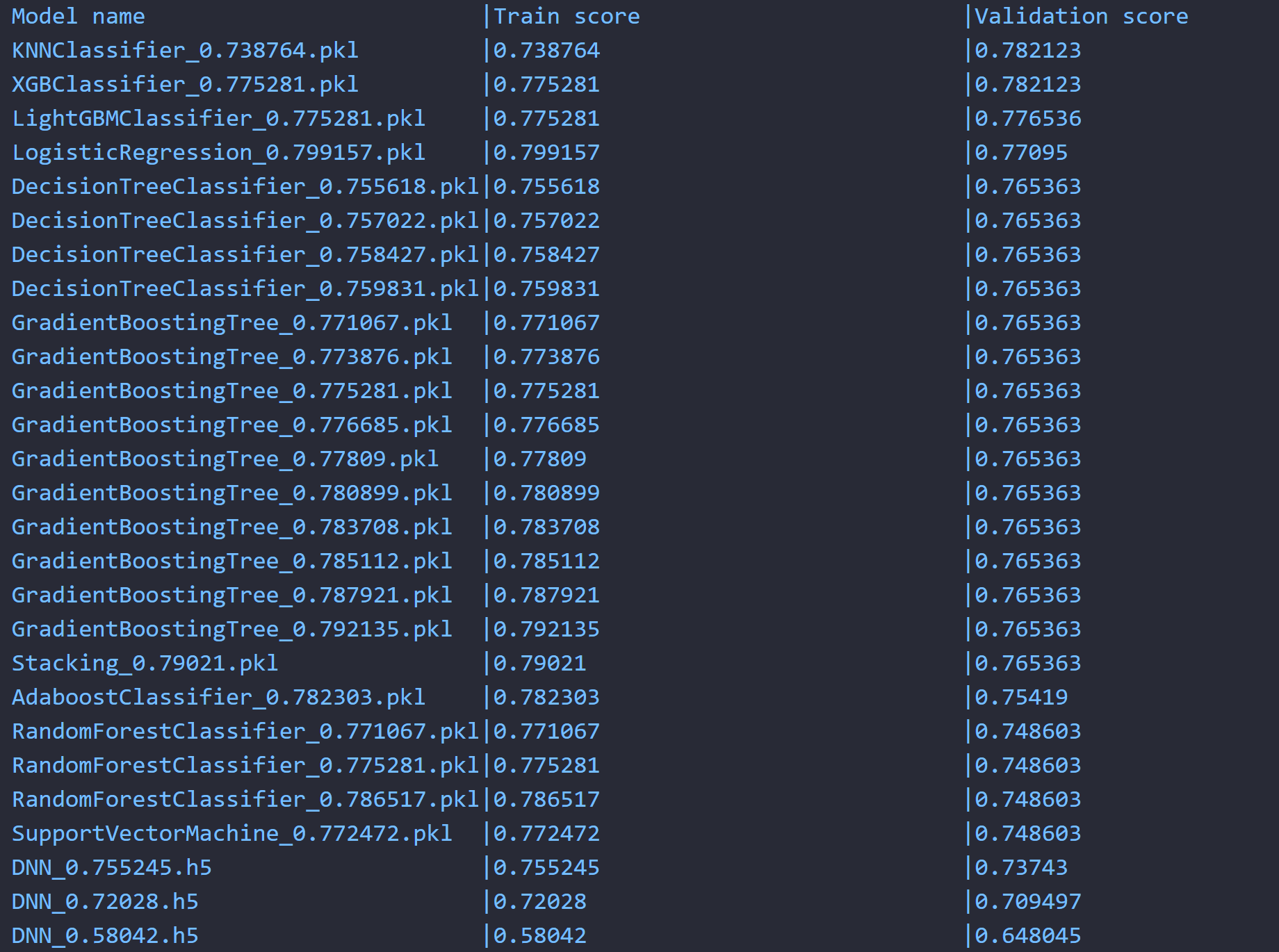
When we need to try to use functionality of automl-engine, just init :class: ClassificationAutoML, then use :func:fit to start our training step.
What we need to do is to wait it to finish, also this is supported with process step, you could get some insights which algorithm is used and process status.
That’s it all you need to get best models based on your dataset!
If you need to get model prediction based on best trained model, that’s easy just call predict function based on test data file like bellow code.
>>> file_load_test = FileLoad(file_name="test.csv", file_path = r"C:\auto_ml\test")
>>> pred = auto_est.predict(file_load=file_load_test)
Then we could get whole trained models’ evaluation score for each trained model score, we could get best trained model based on validation score if we would love to use trained model for production, one important thing is that these models are stored in local server, we could use them any time with RESTFul API calls.
Cloud support¶
If we want to use GCP cloud storage as a data source for train and test data, what needed is just get the service account file with proper authority, last is just provide with parameter: service_account_name and file local path: service_account_file_path to FileLoad object, then training will start automatically.
>>> file_name="train.csv"
>>> file_path = "gs://bucket_name"
>>> service_account_name = "service_account.json"
>>> service_account_file_path = r"C:\auto_ml\test"
>>> file_load = FileLoad(file_name, file_path, label_name='Survived', service_account_file_name=service_account_name, service_account_file_path=service_account_file_path)
>>> auto_est = ClassificationAutoML()
>>> auto_est.fit(file_load=file_load)
Sklearn style¶
If we have data in memory, we could also use memory objects to train, test and predict with auto_est object, just like our friend scikit-learn.
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> x, y = load_iris(return_X_y=True)
>>> xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size=.2)
>>> auto_est = ClassificationAutoML()
>>> auto_est.fit(xtrain, ytrain)
>>> score = auto_est.score(xtest, ytest)
>>> pred = auto_est.predict(xtest)
>>> prob = auto_est.predict_proba(xtest)
Regreession support¶
Full functionality for both classification and regression is same, so the only difference is to change imported class from ClassificationAutoML to RegressionAutoML just like snippet code
>>> from automl.estimator import FileLoad, RegressionAutoML
>>> file_load = FileLoad(file_name="train.csv", file_path = r"C:\auto_ml\test", label_name="label")
>>> # Just change this class
>>> auto_est = RegressionAutoML()
>>> auto_est.fit(file_load=file_load, val_split=0.2)
Key features¶
machine learningandneural network modelsare supported.
Automatically data pre-processingwith missing, unstable, categorical various data types.
Ensemble logicto combine models to build more powerful models.
Nueral network models searchwithkerastunnerto find best hyper-parameter for specific type of algorithm.
Cloud filesare supported like:Cloud storagefor GCP or local files.
Loggingdifferent processing information into one date file for future reference.
Processing monitoringfor each algorithm training status.
RESTful APIfor API call to get prediction based on best trained model.
Algorithms support¶
- Current supported algorithms:
Logistic Regression
Support vector machine
Gradient boosting tree
Random forest
Decision Tree
Adaboost Tree
K-neighbors
XGBoost
LightGBM
Deep nueral network
- Also supported with Ensemble logic to combine different models to build more powerful model by adding model diversity:
Voting
Stacking
- For raw data file, will try with some common pre-procesing steps to create dataset for algorithms, currently some pre-processing algorithms are supported:
Imputation with statistic analysis for continuous and categorical columns, also support with KNN imputaion
Standarize
Normalize
OneHot Encoding
MinMax
PCA
Feature selection with variance or LinearRegression or ExtraTree
Insights of automl-engine¶
Insight for logics of automl-engine:
Load data from file or memory for both training and testinig with class
FileLoad, support with GCP’sGCSfiles as source file.Build processing pipeline object based on data.
(1).
Imputationfor both categorical and numerical data with different logic, if data missing column is over a threshold, will delete that column. Support with algorithmKNNImputerto impute data orSimpleImputerto fill missing data.(2).
OneHot Encodingfor categorical columns and add created columns into original data.(3).
Standardizedata to avoid data range, also benefit for some algorithms likeSVMetc.(4).
MinMaxdata to keep data into a 0-1 range.(5).
FeatureSelectionto keep features with a default threshold or using algorithm withExtraTreeorLinearRegreesionto select features.(6).
PCAto reduce dimenssion if feature variance over a threshold and just keep satisfied features.Build a
Singletonbackend object to do file or data related functions.Build training pipeline to instant each algorithm with a
factoryclass based on pre-defined used algorithms.Build a
SearchModelclass for each algorithm to find best parameters based onRandomSearchorGridSearch.Pre-processing pipeline
fitandtranform, save trained pipeline into disk for future use.Start
trainingwith training pipeline with processed data with doing parameters search to findbest parameter's model, also combined with Neural network search to find best neural models. If needvalidationwill use some data to do validation that will reduce training data size, or could use traindedauto_mlobject to do validation will also be fine.Use
Ensemblelogic to dovotingorstackingto combine trained models as a new more diverse model based on best trained model.Evaluateeach trained models based on validation data and return a ditionary withtraining model name,training scoreandvalidation score.Support to
export trained models into a pre-defined folderthat we want.Support
RESTful APIcall based on best trained model based ontest score.